One of the many subtasks when performing a prediction scheme is adjusting for mediating and confounding variables. But what is a mediator, what is a confounder, and why include thhem? Counfounder and Mediators can be illustrated using a causal diagram (From this Wikipedia page):
As you can see, a confounding variable is something that confounds or ‘confuses’ the relationship between an exposure and an outcome. The relationship between an exposure X and an outcome Y is influenced by a confounding variable Z. A mediating variable connects an exposure to an outcome where otherwise would not be. The relationship between an exposure X and an outcome Y is influenced by a mediating variable Z.
Here, I will show how MCCV can be used to identify confounders and mediators.
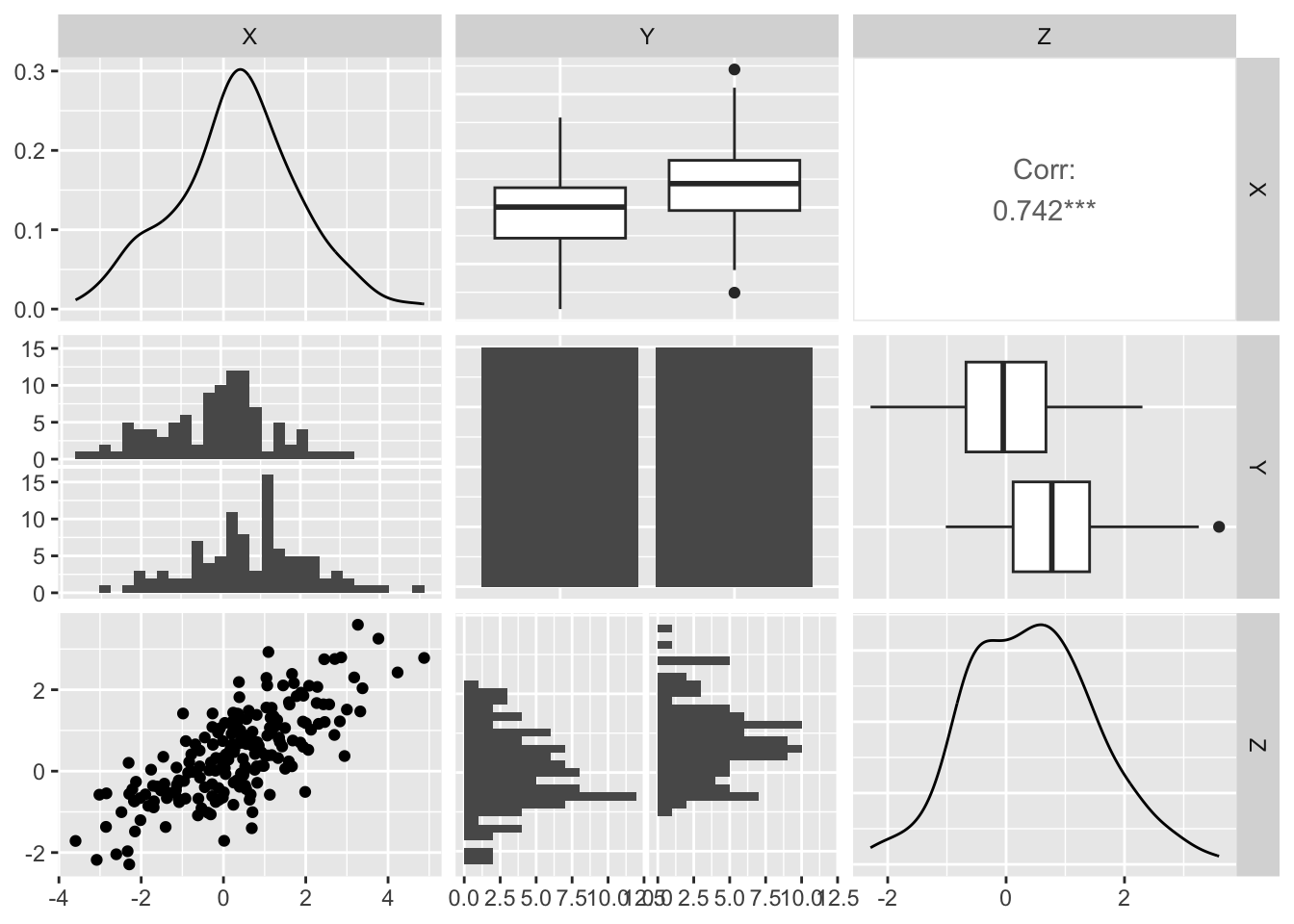
Generate dataset with an effect X, outcome Y, and a confounder Z variables
The random variable Z generates X and Y. Any correlation between X and Y is therefore spurious
Show The Code
import numpy as npN=100Z1 = np.random.normal(loc=0,scale=1,size=N)Z2 = np.random.normal(loc=1,scale=1,size=N)Z = np.concatenate([Z1,Z2])import scipy as scY = np.concatenate([sc.stats.bernoulli.rvs(z,size=1) for z in (Z -min(Z)) / (max(Z) -min(Z))])X = Z + np.random.normal(loc=0,scale=1,size=len(Z))
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
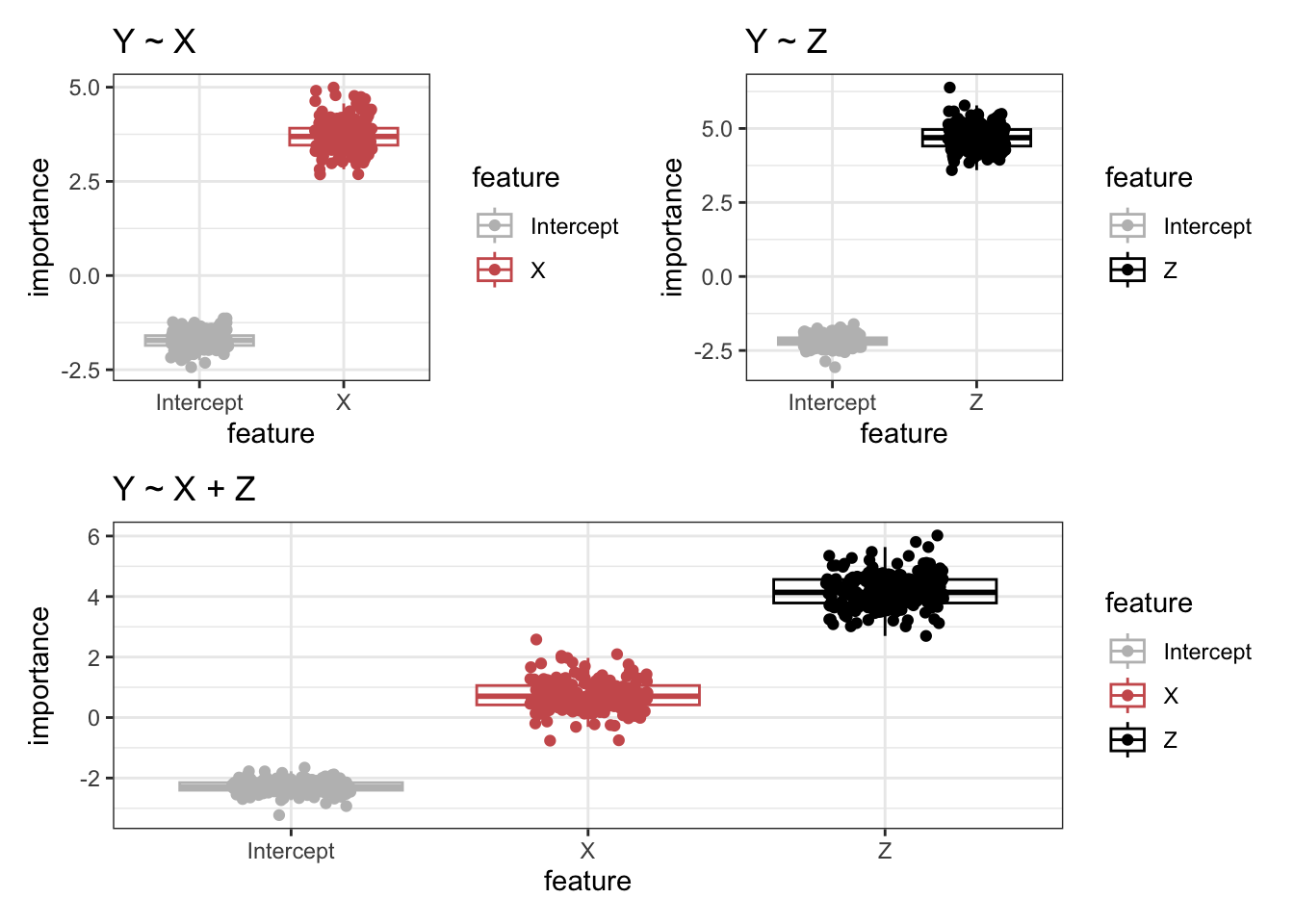
In this example, Z is confounding the relationship between X and Y. The ‘Y ~ X’ model shows that X is very important in predicting Y. However, when Z is included in the model ‘Y ~ X + Z’, you see that Z remains very important but X is no longer important for predicting Y. This toy example had Z causing Y and Z causing X, and any relationship between X and Y was spurious. Therefore, including X and Z as predictors showed only the importance of Z in predicting Y.
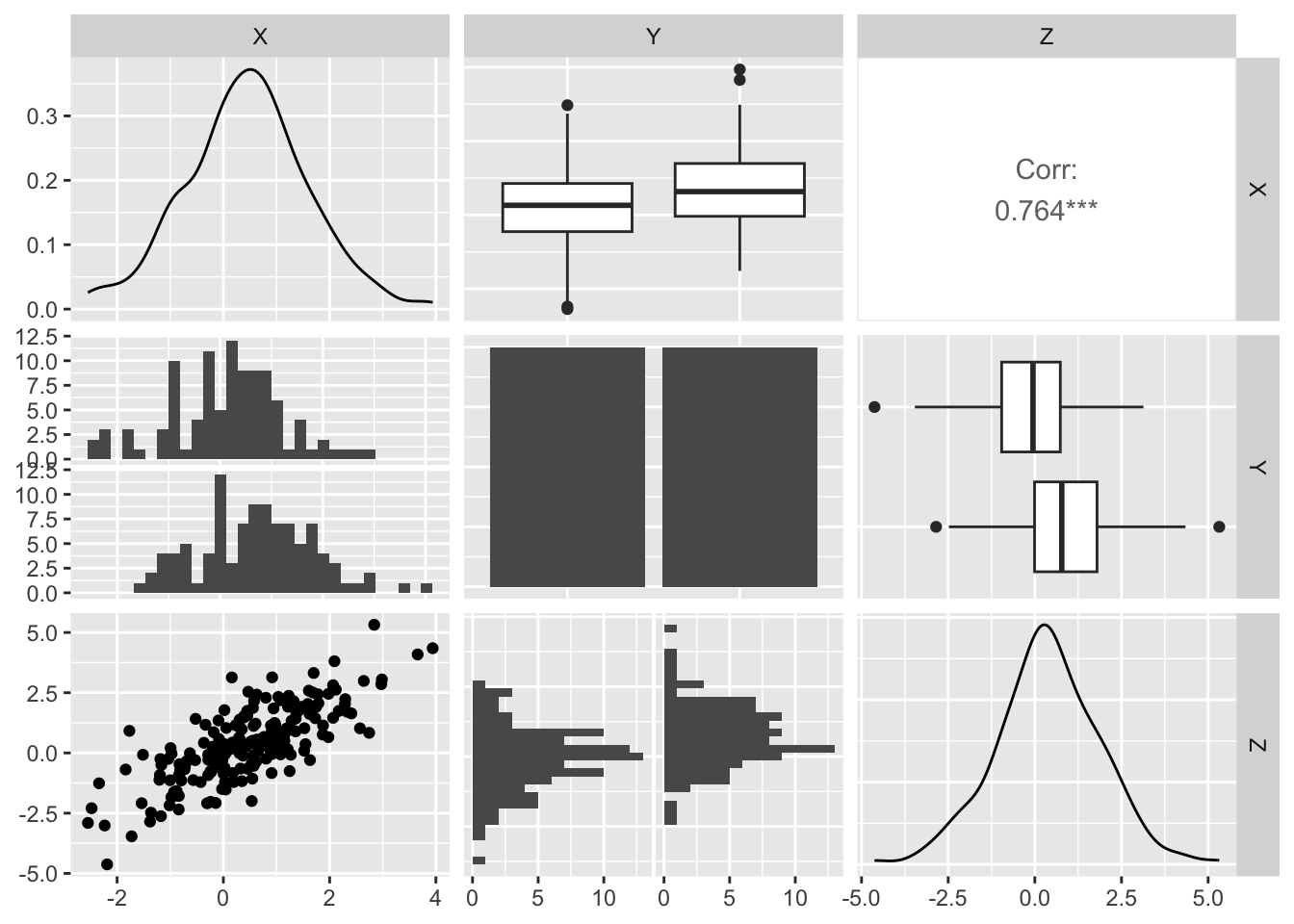
Generate dataset with an effect X, outcome Y, and a mediator Z variables
The random variable X generates Z which generates and Y. Any correlation between X and Y is therefore spurious
Show The Code
import numpy as npN=100X1 = np.random.normal(loc=0,scale=1,size=N)X2 = np.random.normal(loc=1,scale=1,size=N)X = np.concatenate([X1,X2])import scipy as scZ = X + np.random.normal(loc=0,scale=1,size=len(X))Y = np.concatenate([sc.stats.bernoulli.rvs(z,size=1) for z in (Z -min(Z)) / (max(Z) -min(Z))])
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
Warning in py_to_r.pandas.core.frame.DataFrame(object): index contains
duplicated values: row names not set
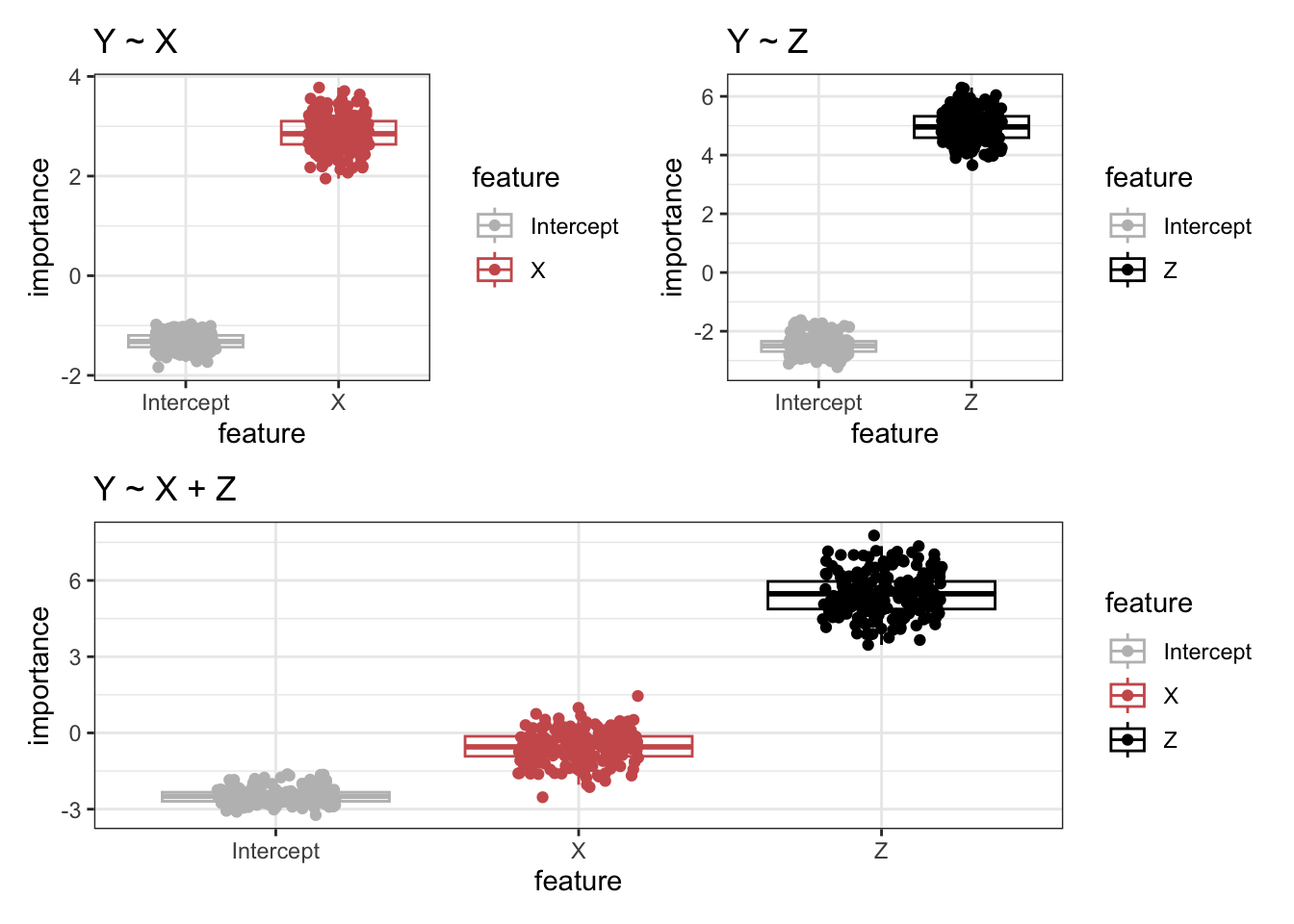
In this example, Z is a mediating relationship between X and Y. The ‘Y ~ X’ model shows that X is very important in predicting Y. However, when Z is included in the model ‘Y ~ X + Z’, you see that Z remains very important but X is no longer important for predicting Y. This toy example had Z causing Y and X relating to Y through Z, and any relationship between X and Y was mediated through Z. Therefore, including X and Z as predictors showed only the importance of Z in predicting Y.